
As we near the end of the 2025 fintech conference circuit, I can say with confidence that the most overhyped technology this year was agentic AI.
Yet despite the hype (which can, at times, become absolutely overwhelming), agentic AI is much more than a buzzword. It represents a significant change in the capabilities underpinning modern software systems.
And because software ate financial services a long time ago, we all need to care about that change and what it means for those building in this industry. This is especially true within the realm of risk decisioning, which is always the riskiest and most potentially lucrative area of disruption for any new analytic model or technology.
So, in today’s essay, I will attempt to define what agentic AI is, how it’s different from generative AI (and why that difference isn’t just semantic), and how we should think about redesigning risk decisioning processes and systems around agentic AI.
What is Agentic AI? (And why is it different from generative AI?)
Let’s start at the beginning, with large language models or LLMs.
LLMs are the foundation of almost everything we now call “AI.” They’re trained on mountains of data (mostly scraped from the internet) to do one deceptively simple thing: predict the next word (or “token”) in a sequence. That’s it. LLMs are just highly optimized autocomplete engines.
From that very simple premise, we’ve gotten something astonishingly useful. These models have learned enough patterns about how humans express ideas that they can now produce new, (mostly) coherent patterns in a variety of different modalities.
The obvious first use case for LLMs, and where this field of artificial intelligence first garnered mainstream attention (pun intended!), is to generate content.
This is where the term generative AI comes from. It describes a class of software applications, built on LLMs, that produce new content based on the patterns observed in the data used to train the underlying model. You give it a prompt (“Explain Basel III like I’m five” is a prompt I have personally used), and it spits out text, images, code, or speech.
You likely already know all of this, but it’s important to establish how LLMs and generative AI work as a baseline before we discuss agentic AI. This is because agentic AI is not simply a smarter or more capable large language model. Agentic AI is a fundamental rearchitecting of how value is created using the LLMs we already have.
The assumption underpinning early generative AI applications was that the LLMs themselves were capable (with some guardrails like retrieval-augmented generation, fine-tuning, and prompt mediation) of fulfilling most of the needs that end users had. And, to the extent that wasn’t the case, those problems would be fixed by more advanced models, trained on even larger datasets.
However, as we have learned more about how LLMs work and what it takes to improve their performance, it has started to become evident that this was a bad assumption.
The performance curve of these models doesn’t stretch infinitely upward; it flattens. We’ve essentially mined the internet for all its worth — Wikipedia, Reddit, GitHub, etc. — and that trove of text is finite. The next order of magnitude in model scale would require data that simply doesn’t exist in usable quantity or quality.
And even if you could find enough new text to feed the beast, bigger models don’t fix the core problem: the model’s job is still to predict what words are likely to come next, not to know what is true. The statistical nature of language modeling guarantees a certain level of hallucination — confident nonsense delivered with perfect syntax.
Researchers have shown that hallucination is not a side effect of bad training data or underpowered architectures; it’s an inherent feature of how probabilistic content generation works. The model can only infer patterns from the data it’s seen, not verify facts it hasn’t. No matter how large or aligned an LLM becomes, it will always be capable of making astonishingly dumb and inexplicable mistakes.
Put simply, we may be nearing the ceiling on what scale alone can achieve.
More parameters, more GPUs, and more data will yield incremental gains, not qualitative leaps. To go further, we need to rethink the architecture — not make the autocomplete smarter, but give it structure, context, and the ability to act in the world.
That’s where agentic AI enters the picture: not as a bigger model, but as a better system built around the models we already have.
So, what exactly is an agentic AI system?
In simple terms, it’s an LLM with a few additional capabilities wrapped around it:
- The ability to use tools (like a web browser, calculator, or code interpreter) when needed.
- Memory, so it can remember what it’s done before and why.
- Planning and orchestration logic, so it can break a task into steps and decide which tool or model to use for each one.
Here’s a simple visual, courtesy of Anthropic:
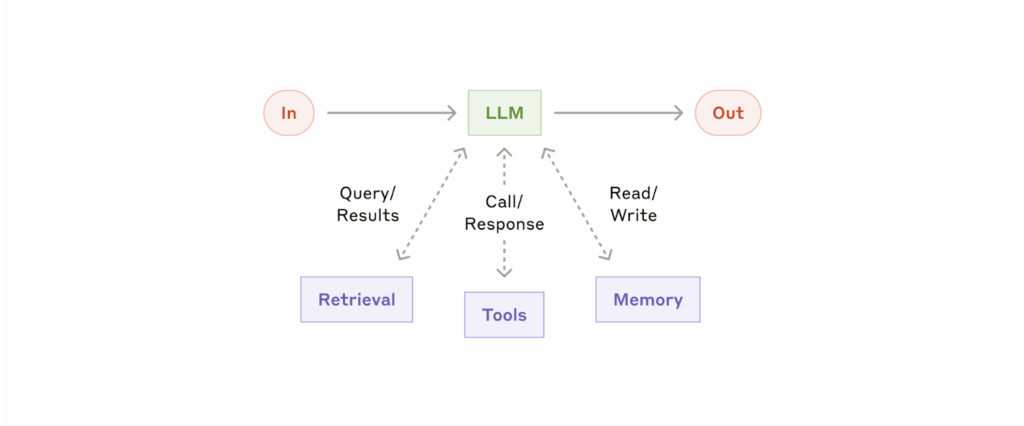
This may seem a bit imprecise, but trust me: it’s a framework that has already proven highly disruptive.
Take the big AI labs — OpenAI, Anthropic, Google — as an example. Without a lot of fanfare, the flagship consumer-facing apps created by these companies (ChatGPT, Claude, Gemini) have evolved from simple content generation services to full-on agentic decisioning systems.
When ChatGPT first launched, it was essentially a slick interface on top of a large language model — a text box connected to a text generator. You prompted it; it replied. It was clever, useful, and occasionally unhinged. But it was fundamentally static — a smart autocomplete engine with a chat bubble.
Now? It’s a full-blown agentic system hiding in plain sight.
OpenAI has quietly turned its flagship consumer app into a bundle of capabilities orchestrated around that same language model:
- A browser that retrieves real-time information.
- A Python interpreter that can analyze data, run simulations, or draw charts.
- An image generator that translates text to visuals.
- A memory layer that recalls prior interactions.
- And, perhaps most importantly, a router — an invisible orchestration layer that decides when to use which tool, and which model variant to invoke.
In other words, when you ask ChatGPT a question today, you’re not interacting with a single model. You’re triggering a decision tree inside a larger system. The system interprets your intent, plans a path, and dynamically assembles the steps needed to deliver a result — sometimes by writing code, sometimes by searching the web, sometimes by reasoning directly in text.
The generative model is still there at the center, but it’s now just one component of a larger machine — a kind of cognitive engine surrounded by lots of additional plumbing.
Anthropic’s Claude and Google’s Gemini are on the same trajectory. Each is becoming less a chat interface and more a coordinator — something that can decide what type of reasoning to perform, which data sources to query, or when to hand control back to you.
This quiet shift is why consumer AI feels both familiar and strangely new right now. The front-end experience — a conversation in a text box — hasn’t changed much. But behind the scenes, the architecture has flipped from generation to orchestration.
And that brings us to risk decisioning, which is, essentially, just a series of orchestrated steps designed to turn structured and unstructured data into high-confidence fraud, compliance, and credit decisions.
Applying Agentic AI to Risk Decisioning
So, here’s the question: Can agentic AI systems add value within the context of banks’ and fintech companies’ fraud, compliance, and credit risk decisioning processes?
And if so, how?
To answer these questions, we first need to understand the history of risk decisioning in financial services and how different generations of technology have changed it.
So, fire up the Taylor Swift playlist, and let’s do a quick eras tour!
Era 1: Fully Manual Underwriting | Everything up to (roughly) 1989
This was the era of branch-based distribution and human-driven underwriting. Loan officers worked off of their institutions’ written lending policies, but individual decisions were made entirely by hand and were heavily influenced by the relationships those loan officers had with prospective borrowers.
This approach to risk decisioning was slow (in the old days, believe it or not, loan officers would call into the credit bureaus and have them read a consumer’s file to them over the phone) and subject to significant bias (fair lending laws had been in place since the early 1970s, but there was still a lot of discrimination in individual lending decisions).
However, the benefit of this fully manual approach to risk decisioning was that it was highly flexible and capable of parsing nuance. A human loan officer, armed with an understanding of the full context of a prospective borrower’s situation, was capable of safely approving loans that might have, at a surface level, appeared too risky.
Era 2: Manual Underwriting, With Tools | Approximately 1989 to 2007
Loan applications were still primarily submitted through branches and call centers, although a few early innovators had begun to utilize the internet to acquire customers. On the back end, risk decisions were still being made manually, but loan officers’ jobs became significantly faster and easier thanks to the introduction of specific risk decisioning and case management tools.
The most famous of these, obviously, was the FICO Score, which was introduced in 1989.
For loan officers, the FICO Score, with its seemingly magical ability to predict future default rates with extraordinary precision, was a revelation. It felt, I imagine, a little bit like how it felt to folks in the 1920s when upright electric vacuum cleaners started to become commonplace. Yes, you were still cleaning the house by hand every week, but this new tool saved you a significant amount of time and energy.
In addition to the efficiency gains, these new tools significantly reduced the inconsistency and bias that had been rampant in lending up to that point and led to fairer, more transparent decisions.
However, the cost, as Martin Kleinbard noted in his excellent research report — How Cash Flow Data Can Defuse the Credit Score Time Bomb — was that lenders, over time, became overreliant on these new tools and less disciplined in their use of time-tested risk decisioning techniques like debt-to-income analysis.
Era 3: Fully Automated Digital Risk Decisioning | 2007 to Now
In the mid-2000s, the industry made a big leap forward.
The proliferation of deterministic risk decisioning and case management tools — standardized electronic credit files, credit scores built with machine learning, business rules engines, fraud investigation systems — combined with the maturation of digital customer acquisition channels, allowed companies such as Bill Me Later, LendingClub, and OnDeck Capital to assemble lending workflows in which a vast majority of applicants could be automatically decisioned, end-to-end, with no human intervention.
This was a massively important development in the business of lending because it showed companies and their investors a SaaS-like vision of the future: maximum throughput with minimum OpEx investment.
To return to our cleaning analogy, it was like when iRobot introduced the Roomba in 2002. Suddenly, it seemed theoretically possible to anyone who was tired of cleaning their house (i.e., every adult in the world) that they might never have to pick up a broom or push a vacuum cleaner around ever again.
Of course, as we all know, that didn’t happen. The Roomba craze died down. Not because fully autonomous vacuuming technology isn’t valuable, but because the constraints necessary to make it work (a level, unchanging, clutter-free space) limit the ability to get what we really want out of it (a thoroughly clean house).
Fully automated digital risk decisioning is similar. When it works, it’s great; producing consistently fair, transparent, and profitable decisions and efficient, convenient experiences for lenders and their customers.
But when it doesn’t work — when applicants get stuck in the digital account opening process or unstructured data breaks a carefully-constructed scoring model or a financial crime risk needs to be investigated — it leads to burdensome operational logjams and, more importantly, missed opportunities.
Which brings us back to our question: Can agentic AI systems add value within the context of banks’ and fintech companies’ fraud, compliance, and credit risk decisioning processes?
The short answer is yes.
However, I want to put the capabilities of AI agents for risk decisioning in the proper context, because, while I believe they can add significant value, they are also not without their frustrations. And we will need to address those frustrations if this next era of agent-augmented risk decisioning is to be successful.
Era 4: Agent-Augmented Risk Decisioning | ?
I’ve used the terms “deterministic” and “probabilistic” throughout this essay, but I haven’t defined them yet. So let’s do that now.
A deterministic system is one where the same input always produces the same output. There’s no randomness — the rules are fixed and the results are consistent and predictable.
A probabilistic system is one where the same input can produce different outputs, because it relies on probabilities or randomness. A certain amount of uncertainty is baked in.
To return to our cleaning analogy one final time, brooms are deterministic systems. You position them against a surface, apply a little force, and you get a consistent and predictable result — same thing for upright vacuums. Even Roombas, which appear, in their function, to have some rudimentary form of intelligence and autonomy, are really just complex, rule-driven, deterministic systems.
LLMs, which are the foundation of agentic AI, are not deterministic systems. They are not a more sophisticated robot vacuum. LLMs are toddlers.
Now, if you don’t have kids, or it’s been a while since you had little kids, allow me to quickly explain what it’s like trying to get toddlers to help you clean your house.
To call it agonizing would be an understatement. You ask them to do one simple thing, something they’ve done countless times before, and they mess it up. You ask them a straightforward question about what they’re currently doing, and they lie, seemingly for no reason. You send them to do something in another room, outside your direct line of sight, and you find them 40 minutes later, not having accomplished that thing because they got confused or distracted along the way.
To be fair, LLMs aren’t exactly like toddlers. This is a fun, but imperfect analogy. LLMs aren’t the ones messing up your house in the first place. And they are not, in any way, obstinate, the way that little kids are when you ask them to do something they don’t want to do.
Having on-demand access to LLM inference is more like being able to spin up an unlimited swarm of perfectly cheerful and hardworking toddlers.
But still … fundamentally, they’re toddlers.
And what’s most frustrating about trying to get toddlers to help you clean your house is that, despite all of the challenges I just illustrated, they have the potential to be really helpful!
Toddlers are clever. They can understand vague instructions (go clean the … you know … the thing in the place!) They can ask for help or clarification when they don’t understand something. They can assess the state of their environment and adjust their strategies accordingly. They can use tools. They can even work cooperatively with each other to accomplish a goal (my kids usually only team up when they’re doing something nefarious, but you get the point).
Toddlers’ potential to be helpful in house cleaning is immense, and I know this firsthand because my wife and I occasionally visit other parents’ houses, where we get to see glimpses of how helpful their toddlers are in cleaning their homes.
This suggests that the poor results in our house are not the inevitable result of relying on the probabilistic brains of small children, but rather due to my wife and I’s specific failings in toddler prompt engineering.
The same will be true of LLMs in risk decisioning.
Think Different
The essential challenge with LLMs is that they don’t fit neatly into the operational and technological risk decisioning frameworks that financial institutions have been perfecting for the last five decades.
We’ve gotten really good at blending together fully automated, deterministic decisioning systems (the Roombas) with the tool-augmented human underwriters and risk analysts (the brooms). We know what that looks like:
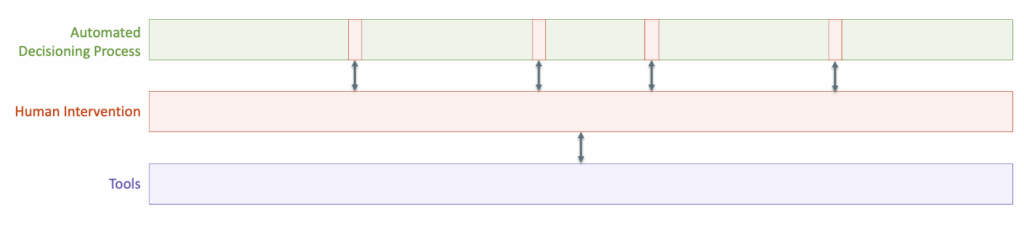
The ideal mix of deterministic software and manual human intervention differs, depending on the product.
Most consumer lending products — credit cards, BNPL, personal loans, auto loans — lend themselves well to near-complete automation (with minimal human intervention), thanks to the availability and homogeneity of the underlying risk data and the comparatively small individual loan amounts.
Mortgages and commercial loans sit on the other end of the spectrum; their large loan sizes and heterogeneous customer profiles require and justify bespoke, highly manual decisioning processes (with a little bit of automation sprinkled in).
Small business loans sit, unfavorably, somewhere in between these two ends of the spectrum, needing the bespoke, nuanced handling of commercial loans, but lacking the size and profitability to justify it.
However, now that we can add LLMs (our eager, hardworking swarms of toddlers) into the process, the picture can and should change. We can add a whole new, differentiated layer of intelligence into our framework:
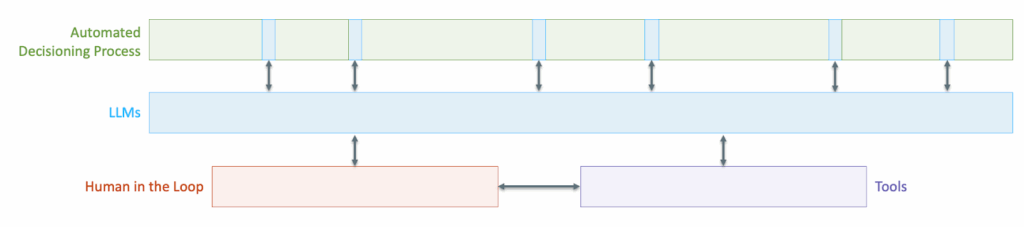
By adding probabilistic software into the mix for lending products that can’t be fully automated using deterministic software alone, we can dramatically and positively alter the traditional assumptions about the profitability of those products. This will be particularly noticeable in small business lending, but the effects will eventually be seen everywhere.
However, getting to this end state will require financial institutions to think different.
Just as the AI labs realized that the utility of their LLMs would be severely limited without a deterministic software layer wrapped around them, financial institutions will need to see that those same deterministic software guardrails as essential if they want to harness the good qualities of LLMs (flexible inputs, fluid reasoning, iterative problem-solving, etc.) while minimizing the bad (hallucinations, inconsistencies, opacity, etc).
This is how we get to agent-augmented risk decisioning.
And once we get there, what can we do with it?
I’m so glad you asked!
Refactoring Risk Decisioning with Agentic AI
There are countless ways that the risk decisioning process may change with the infusion of LLMs and the agentic decisioning systems we wrap around them. Too many to fully explore in this essay.
However, there are three specific categories of use cases that I want to highlight:
- Cleaning
- Communicating
- Orchestrating
Cleaning
Despite the progress that we have made over the last 50 years in cleaning and standardizing the data inputs that drive risk decisioning processes in financial services, there is still a lot of messy and unstructured data: receipts, PDFs, tax returns, emails, consumer statements in credit files, etc.
Lenders already have deterministic scoring models; what they lack is clean, contextual data that those models can use.
Agentic AI can take on the cleaning and categorization work that human analysts and junior underwriters currently spend hours doing:
- Document parsing and data extraction: Reading pay stubs, bank statements, leases, or tax forms and transforming them into structured tables. Taktile’s work on tabular LLMs shows how models can now translate free-form financial text into decision-ready features.
- Entity matching and cross-verification: Comparing business addresses, ownership data, or EINs against public sources — even verifying that a listed business location matches Google Street View imagery.
- Data enrichment: Pulling supplementary data from APIs — bank feeds, accounting systems, or KYC registries — to fill gaps before a scoring model runs.
- Qualitative summarization: Distilling unstructured text (e.g., business plans, management bios, or customer reviews) into credit-relevant signals.
- Anomaly detection: Identifying irregularities or data mismatches before they propagate downstream.
In consumer credit, much of this is already automated. But in mortgage, SMB, and commercial lending, creating clean, usable data remains a bottleneck — and an enormous opportunity.
Communication
One of the biggest points of friction in the lending process, particularly for operationally-intensive products like mortgages and small business loans, is customer communication. Translating deterministic outputs into human language, guidance, and context.
Use cases here include:
- Real-time coaching and application support: Conversational copilots that help applicants understand requirements, estimate their eligibility, and review and troubleshoot submitted applications and supporting documents. This is a critical service that has historically been provided by human loan officers, but with agentic AI, it can now be scaled up and made available on demand, 24x7x365 (picture a small business owner submitting a loan application at 1:00 AM after she finishes closing her books for the month).
- Personalized adverse action notices: Turning generic reason codes into clear, actionable explanations (“Your average daily balance dropped below $5,000; maintaining that threshold could improve approval odds next time”). Taking it a step further, imagine being able to spin up a personal AI “credit coach” for each declined applicant that persists beyond that rejection and helps them improve their financial situation and reapply once their odds have improved.
- Post-origination requests and account modifications: Agentic AI can handle credit lifecycle events — such as credit limit increase requests — by parsing the customer’s request (how much is he asking for?), dynamically retrieving updated financial data, kicking off an eligibility check within the deterministic rules engine, and explaining the outcome to the customer in plain language.
This layer bridges the gap between precision and empathy — between what the system decided and how to make sense of it.
Orchestration
Even the best deterministic systems freeze when they encounter ambiguity: missing data, conflicting policies, or borderline applicants. That’s where orchestration comes in — using agentic AI to plan, sequence, and execute the multi-step workflows that humans currently manage by email and Excel.
This is the most intriguing layer of use cases for agentic AI. It’s also the one that is most fraught with risk because it puts trust in the LLM to not only execute a specific task, but to assess, plan, and oversee how that task is completed.
From an engineering perspective, agentic orchestration is often done by assigning specific, focused tasks to specific sub-agents, which are then overseen by a centralized orchestration agent. This “swarm” approach is preferable for complex workflows because it’s modular, observable, and resilient. Unlike a monolithic agent that tries to do everything in one context (and often collapses under its own reasoning load), a swarm isolates complexity: each agent handles a focused function, its outputs are testable, and failures don’t cascade. This compartmentalization improves transparency, allows targeted tuning, and supports human-in-the-loop oversight, making it ideal for regulated domains like lending, where scalability must coexist with explainability and control.
Here’s a simple visualization of this approach, from Anthropic:
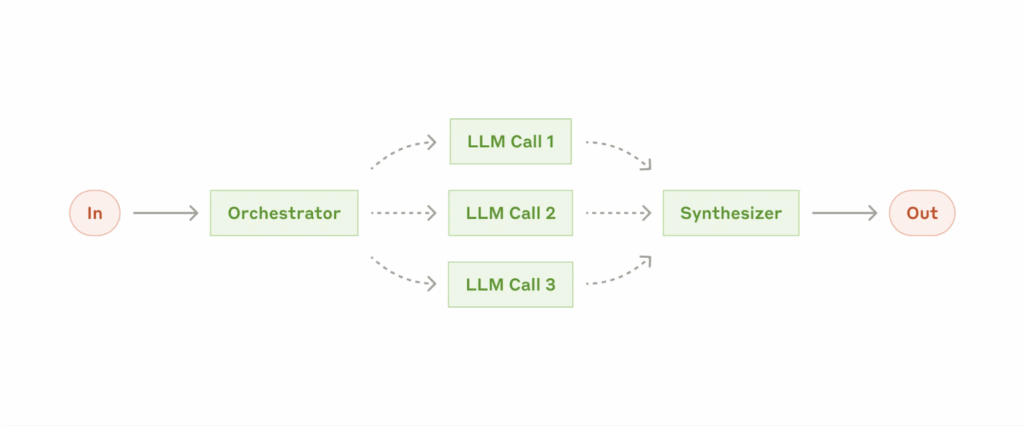
Key use cases for agentic orchestration include:
- Exception handling and edge-case triage: Swarms of sub-agents can investigate outliers — fetching missing documents, checking alternative data sources, testing “what-if” scenarios (e.g., extending income averaging from 6 to 12 months), and summarizing results for human review.
- Dynamic fraud and compliance monitoring: Continuously scanning for new patterns (emerging fraud typologies, AML flags, policy drift) and drafting updates to internal rules or watchlists.
- Portfolio and early-warning systems: Monitoring live loan performance, behavioral signals, and macro trends to identify deteriorating cohorts before losses rise.
- Policy simulation and sandboxing: Running counterfactuals (“What if we loosened DTI thresholds?”) and producing impact analyses for risk committees — compressing weeks of analysis into hours.
These agentic orchestration capabilities turn disjointed workflows into adaptive, closed-loop systems. Humans still make the final decisions; agents just streamline the steps between them.
The Payoff
Agentic AI is ready now. It does not require a step-function increase in the capabilities of LLMs. With a modern, deterministic risk decisioning platform, the LLMs we have today can be applied across the customer lifecycle and within complex, high-risk decision flows. And the companies that move early — who learn quickest, iterate rapidly, and build operational fluency with AI agents — will have the opportunity to build a competitive advantage.
Implemented thoughtfully, agentic AI won’t replace underwriters or risk analysts, but it will significantly amplify them.
It won’t automate judgment, but it will make judgment far more scalable.
For many consumer credit products, deterministic automation already runs the show. But in mortgage, SMB, and commercial lending, where ambiguity and paperwork still reign, agentic AI has the potential to create a new type of efficiency — one built on reasoning, not just rules.
About Sponsored Deep Dives
Sponsored Deep Dives are essays sponsored by a very-carefully-curated list of companies (selected by me), in which I write about topics of mutual interest to me, the sponsoring company, and (most importantly) you, the audience. If you have any questions or feedback on these sponsored deep dives, please DM me on Twitter or LinkedIn.
Today’s Sponsored Deep Dive was brought to you by Taktile.

Taktile is the agentic decision platform powering the financial services industry, helping institutions realize value from agentic AI in weeks rather than months.
The platform includes purpose-built agents for financial services that are ready to use and can be tailored in just a few days. Labor-intensive workflows that once required days transform into instant, automated decisions, dramatically improving efficiency.
Everything happens in one place on Taktile, so teams can bring together AI, rules, data, and their own judgment to create powerful onboarding, credit, fraud, and compliance strategies.
Just as important, Taktile keeps every AI-driven action clear, explainable, and aligned with what institutions and regulators expect — so teams can move quickly, adjust when needed, and stay fully in control.
Work that once took months or years becomes a rapid, iterative practice on Taktile.
