
My first job in fintech, which I got 20 years ago this month, was with a company that provided credit decisioning software to banks.
One of the features of that software product, which I didn’t give a whole lot of thought to at the time, was data aggregation. When a bank was making a credit decision, the software would, in real-time, pull the applicant’s credit file and score from whichever credit bureau the bank preferred. We referred to the service as ‘data aggregation’ because we had pre-built integrations with each of the three credit bureaus (as well as numerous smaller specialty bureaus and alternative data providers), thus aggregating together all of the different data provider options in the market for our clients to pick and choose from.
The banks liked this service because it gave them the flexibility to choose between (or use multiple) data providers, without having to build and maintain all of the integrations themselves. They also liked it because we could build intelligence into the service, allowing us to do things like automated failover (in case a bureau went down) and least-cost routing (pulling data from different providers in a sequence that minimized the client’s overall data acquisition costs).
My company liked this service because it allowed us to spread the costs of each data provider integration across multiple clients, rather than building bespoke integrations for each new project. We also liked it because it allowed us to showcase the innovation that was possible through our product, thanks to the breadth of different data sources that we had access to.
The credit bureaus hated this service.
For most of the 20th century, credit bureaus were local. If you were a bank or retailer looking to make a credit decision, you pulled data from the credit bureau in your city, state, or region (i.e. the bureau that had coverage on the consumers you served). However, by the 1990s, the credit bureau industry had consolidated down to the big three we know today. And while some geographic differences persisted for a while (each credit bureau grew out of a specific region of the country and thus has deeper coverage of the lenders in that region), eventually, the core credit data furnished by lenders became equalized across all three credit bureaus. The credit file became a commodity.
Equifax, Experian, and TransUnion recognized the danger of selling a commoditized product (suppliers have no pricing power), so they set about finding ways to both drill down – differentiating their data products by buying up or partnering to acquire alternative sources of data – and to build up the credit decisoning stack – bundling their data with additional value-added services, including credit decisioning software, and, later, the VantageScore.
This is why my company’s data aggregation service was so strategically annoying to the credit bureaus. It undermined the moat they were trying to build around their commoditized core product. It made it illogical to standardize on one credit bureau (regardless of how much you liked a specific part of their stack) because, with our software, you could seamlessly orchestrate your credit decisioning process across a best-of-breed collection of data, analytics, and technology products from a multitude of different providers.
The reason I’ve been thinking about this lately is that a similar competitive dynamic is beginning to take shape around open banking.
The History of Open Banking Data Aggregation
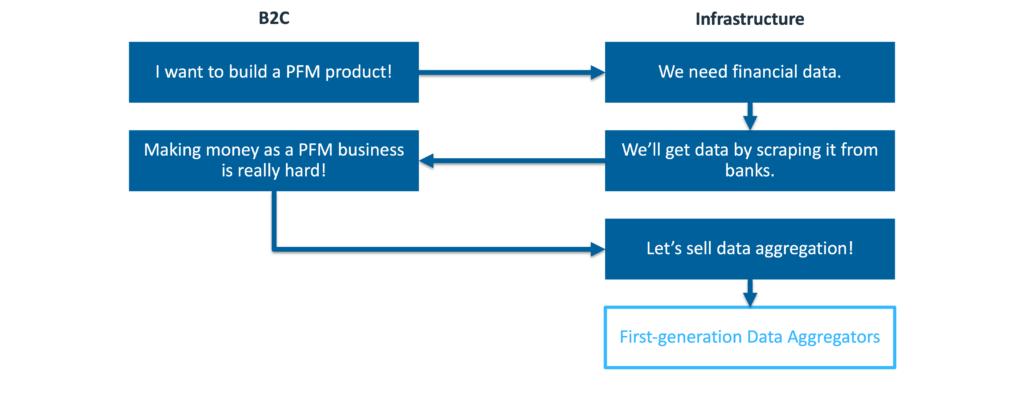
The first generation of modern open banking data aggregators in the U.S. – companies like Yodlee and Finicity – emerged during the dot-com bubble with the vision of pulling together all of the data about consumers’ financial lives (or their digital lives, more broadly, in the case of Yodlee) into one place.
The brilliance of this vision was it was all based on consumer consent (and the ability to build automated bots to scrape consumers’ data using their online banking account credentials), which provided a path to access the required data without having to get permission from the banks that were storing it.
The challenge with this vision was two-fold.
- You had to scrape all of the data yourself, one bank at a time, which was an incredibly heavy lift (and, eventually, a source of legal risk and competitive ire).
- It turns out that the vast majority of consumers don’t really care about having a unified view of their financial lives, which makes personal financial management (PFM) an incredibly tough space to build a large and profitable company.
After struggling through A and realizing the existential danger of B, these companies opted for Door C – pivoting into selling data aggregation as a service to other companies.
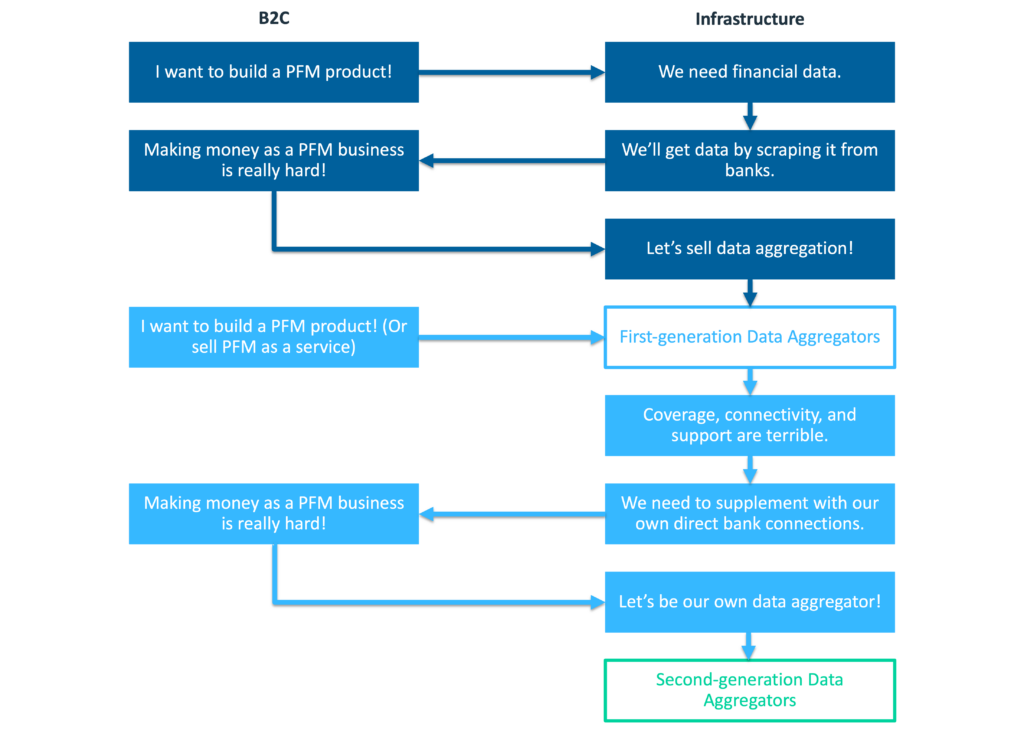
Fast-forward about a decade – right after the great financial crisis – and you see this exact same cycle play itself out again.
A new generation of entrepreneurs, looking at the wreckage wrought by the great financial crisis, decide to build a new generation of PFM products (ignoring the lessons of Yodlee.com and Mvelopes). They work with first-generation data aggregators to get access to bank transaction data, which would have been great, except it turns out that the coverage (number of banks supported), connectivity (reliability of the bank connections), and support (help when things break) provided by these data aggregators are not very good. So, to supplement them, these PFM companies build their own direct bank connections. Eventually, they learn what their predecessors learned – selling infrastructure is more fun than selling B2C or B2B2C PFM tools – and they pivot into becoming data aggregators themselves (Plaid, MX, etc.)
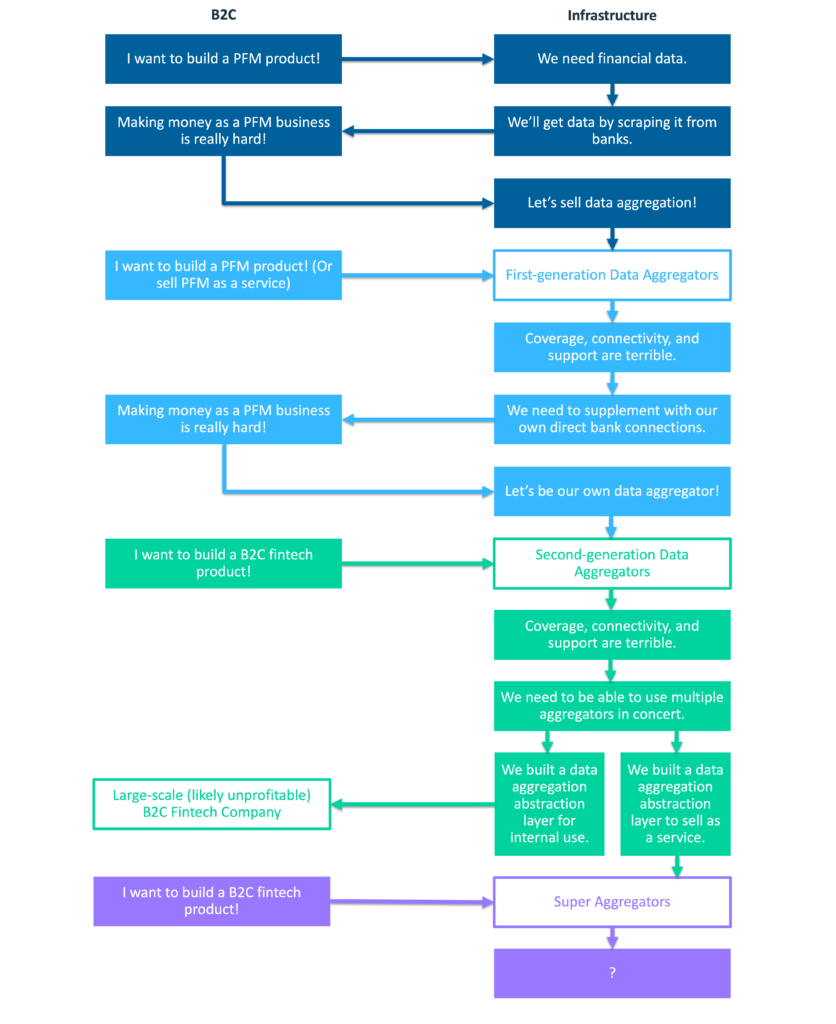
The third time that this cycle plays itself out, there are some important differences.
The first difference is that many more entrepreneurs were interested in building fintech during the second half of the 2010s and the beginning of the 2020s. Thank you, ZIRP!
The second difference is that the second generation of data aggregators figured out how to sell fintech entrepreneurs on new use cases for leveraging bank transaction data. Rather than continuing to hitch their wagon to PFM (which, again, is a really hard business to succeed in), they found new wedge products, such as instant bank account verification.
These two factors drove significant growth for all the players in the U.S. open banking data aggregation market. However, despite the progress that had been made between first-generation and second-generation aggregators, fintech developers and engineers still find themselves frustrated by poor coverage, connectivity, and support.
If you’ve never built a product on top of open banking data aggregation APIs, this may come as a surprise to you.
After all, today’s aggregators are well-funded and generally well-regarded. They have beautiful API docs and impressive top-line integration and performance statistics. Surely, connection, connectivity, and support aren’t still significant problems? It’s 2024!
Ohh reader, take it from someone who has had many detailed conversations (and occasional impromptu therapy sessions) with founders and operators who have been building B2C fintech apps and PFM tools over the last five years – there are still huge problems!
The more interesting question is, what do you do about it?
Well, you do what my first employer did 20 years ago. You aggregate the aggregators!
You build an abstraction layer that sits above all of the individual open banking data aggregation providers. This creates interoperability for the end client, which is then able to build orchestration workflows for utilizing different aggregators in different situations in a way that optimizes cost and conversion rate. For example, based on their different coverage profiles, a client might use Plaid to pull data for a customer trying to connect to a fintech company and use MX to pull data for a customer trying to connect to a community bank.
These data aggregation abstraction layers exist in fintech today.
Some of them are simply part of the internal tech stacks of major B2C fintech companies (neobanks, BNPL providers, digital brokerages, etc.)
However, following in the footsteps of earlier generations, some of them have been spun off into their own infrastructure providers. I call these companies super aggregators.
The Rise of Super Aggregators
Super aggregators are fintech infrastructure companies that provide a unified access point to multiple open banking data aggregators (and other fintech infrastructure providers).
They are most commonly used by early-stage fintech startups to enable the flexibility and redundancy of multiple aggregator integrations without the upfront cost or development effort. However, they are also, in some cases, used by more mature B2C fintech companies that have yet to build their own data aggregation abstraction layer.
The primary business model of super aggregators is resale – they aggregate demand from multiple (often small) end clients and then sell access to individual aggregators’ services at wholesale prices (the exact nature of these reseller arrangements depends on the relationships between the aggregators and super aggregators … they don’t always play nicely with each other).
One of the primary value propositions of super aggregators is the ability to be prescriptive with clients. Because super aggregators see how different clients use different aggregators and because their platforms collect data on the performance of different aggregators, they are uniquely well-positioned to optimize (either programmatically or through consultative selling) their clients’ use of aggregators. On the back end, this optimization is focused on routing – picking the right aggregator for the right use case and financial institution. On the front end, the optimization is focused on the UX – ensuring a smooth account-linking experience that maximizes the client’s conversion rate.
It should be noted that the concept of a super aggregator isn’t new. Multiple second-generation data aggregators (MX, most prominently) took an ‘aggregate the aggregators’ approach when they were first getting started.
Having said that, I think the modern crop of super aggregators – Quiltt, MoneyKit, Meld, and Fuse, to name a few – is worth paying attention to because they are coming along at a very interesting time.
Specifically, there are a few trends that are starting to have a major impact on super aggregators and the open banking market overall:
The U.S. open banking market isn’t winner-take-most.
The value of an ‘aggregate the aggregators’ strategy is proportional to the number of aggregators and other service providers that you are bringing together through your service. In the world of traditional credit bureaus, that was a limiting factor. There’s a reason data aggregation was a feature of my first employer’s product, rather than its own standalone product.
The U.S. open banking market could have evolved in a similar direction if a few key events had played out differently.
There’s an alternate universe out there somewhere in which the Visa/Plaid deal goes through (followed by Mastercard/Finicity and perhaps someone else scooping up MX), and the market consolidates into just a few large players.
That obviously didn’t happen in our universe, though, and the result is that we actually have a reasonably robust and competitive data aggregator ecosystem (more than a dozen legitimate players, by my count), with more entering the market every year (Flinks, Visa/Tink, etc.)
The more open banking data aggregators there are to choose from, the more value super aggregators can provide.
1033 is lowering barriers to entry while leaving the outer boundaries of open banking untamed.
The CFPB’s soon-to-be-finalized rule on Dodd-Frank Section 1033 (i.e. the open banking rule) will have a couple of interesting impacts on the data aggregation market.
First, it should lower the barriers to entry.
While it’s practically impossible for a new company to come into the traditional credit bureau market and meaningfully compete with Equifax, Experian, and TransUnion, 1033 should make it much more feasible for new entrants in the open banking data aggregation market to achieve reasonable levels of coverage and connectivity much faster than earlier generations were able to. Some of these new players will be startups, but a lot of them, I’m guessing, will be established companies that have a strategic interest in data aggregation (Stripe has been dipping its toes in these waters in recent years, and industry experts have speculated that Apple might at some point too).
Second, however, it should be noted that the CFPB’s rule on 1033 won’t cover everything. In fact, the data that is covered under the rule is constrained rather narrowly to deposit accounts, digital wallets, credit cards, and likely EBT accounts and pay-in-four BNPL.
That leaves a whole lot of data (personal loans, auto loans, mortgages, wealth management, payroll, etc.) on the outside, which means that motivated data aggregators will still have an opportunity to prevent their core product from becoming completely commoditized by building coverage and connectivity (through a combination screen scraping and savvy business development) in areas outside the perimeter of 1033.
Taken together, I think that 1033 will be a positive for super aggregators, as it will make it easier for new aggregators to enter the space, while also ensuring enough variability in aggregators’ coverage and connectivity to make the case for why an intelligent abstraction layer is needed.
Banks are going to continue throwing sand in the gears of open banking for the foreseeable future.
Most banks don’t like open banking. Some are so irrational and petulant in their dislike of it that they will go an unjustifiably long way out of their way to sabotage it.
The CFPB’s 1033 rulemaking won’t stop this behavior. Indeed, if the UK’s experience with open banking is any guide, it may make it worse in the short term (when you tell someone exactly what the rules are, you are also telling them precisely how much they can get away with).
This is a problem for the U.S. financial services ecosystem, but it is a boon for super aggregators, which can help clients smooth out the performance rough spots introduced by these bank shenanigans and reduce overall vendor dependency risk.
A good example is Akoya.
Akoya is a data aggregator jointly owned by 11 large banks, Fidelity, and The Clearing House (which itself is owned by a slightly different group of large banks). Strategically, it was built to help banks counter the competitive threat posed by Plaid, MX, and Finicity.
And that’s exactly how the banks have been using it, in ways both subtle and crude.
On the crude side, last year, PNC and Fidelity both announced that they would require all companies that wanted consumer-permissioned access to their data to go through Akoya to get it. This caused quite a stir. PNC, which has data that will fall under the CFPB’s open banking rule, eventually backed off. However, Fidelity, which isn’t going to be subject to the CFPB’s rule, did not.
This was a major wakeup call for fintech companies that were reliant on Fidelity’s wealth management data, and suddenly found themselves cut off. As you might imagine, interest in having a data aggregation abstraction layer increased.
On the more subtle side, fintech companies have found that even when they want to directly integrate with Akoya, it is far more difficult than they would have expected. While most data aggregators design their APIs for software developers, with specific endpoints mapped to common use cases, Akoya’s API has been described to me as more of an OAuth switchboard that bundles together a bunch of disparate APIs, all of which have their own unique architectures. This is likely due to the fact that Akoya’s owners and partners (like the core system providers) are dictating all of the technical requirements for their specific integrations, rather than allowing Akoya the freedom to build to a single, unified set of specifications.
This complexity strengthens the case for using an intermediary to integrate with Akoya, rather than doing it yourself.
The Future of Open Banking and Data Aggregation
So, what does the future look like?
For the super aggregators, it’s likely that we will see them go in one of two different directions.
They will either drill down deeper into data aggregation, finding ways to further optimize the account linking experience and deliver the absolute best coverage and connectivity to their clients (perhaps even building some direct integrations to banks themselves, as the second-generation aggregators did). MoneyKit, whose founders come from Cash App and Quovo (the data aggregator acquired by Plaid in 2019), seems a good candidate to pursue this strategy.
Or they will build up, expanding further into the fintech infrastructure stack, providing a similar aggregation and orchestration value prop in areas like transaction enrichment (Quiltt is doing this in addition to data aggregation) and payments (Meld does this for traditional payment processors and crypto onramps). Some providers, such as JustiFi and Linker Finance, have already taken this strategy to its logical extreme, creating essentially Fintech Infrastructure-as-a-Service (FIaaS).
And, of course, the established data aggregators aren’t sitting still either. The partial commoditization of their core data products is a competitive challenge that they take seriously.
In response, these companies are investing in better coverage and connectivity in areas not covered by 1033 (wealth management seems to be a big priority right now … and it’s a tough space to fully crack with screen scraping). They are also moving up the stack, building out value-added capabilities (payments, cash flow underwriting, fraud/ID verification, personal financial management, etc.) and bundling them into unified products and experiences designed to make their core data products much stickier.
How these two groups – aggregators and super aggregators – evolve independently and how they compete with each other and partner with each other will tell us a lot about the future of open banking in the U.S.
