
Editor’s Note — Today’s essay is a collaboration with my friend Francisco Javier Arceo. Francisco is a Senior Principal Software Engineer at Red Hat and has previously worked as an engineer and data scientist at numerous fintech companies and banks, including Affirm, Fast, and Goldman Sachs. He is also the author of one of my all-time favorite newsletters — Chaos Engineering. Francisco is brilliant, hilarious, and one of the few people who thinks more about the guts of credit decisioning than I do. We wrote today’s essay together, but rest assured, all the smart parts came from his brain. I hope you enjoy it!
Credit risk decisioning, as we think of it today, got its start in the 1950s, when mathematicians and engineers started looking for commercial applications for the theories and technologies that had, for the prior two decades, been primarily employed by the military.
Early pioneers like William Fair and Earl Isaac (the co-founders of FICO) saw an opportunity to apply information theory and statistical analysis to the process of deciding who to give loans to, a process that had been entirely within the realm of human judgment and intuition up until that point.
It’s lucky that they did.
Lending is a fantastic field to apply statistical analysis techniques to because the process of determining whether someone should be approved for a loan or not is a process bound by constraints.
The primary output of any credit risk model is always binary — predicting if a borrower will default on their loan obligation or not.
And many of the inputs into credit risk models have become bound by constraints as well. While Bill Fair and Earl Isaac didn’t have to deal with regulations like the Fair Credit Reporting Act (FCRA) and the Equal Credit Opportunity Act (ECOA) when they first founded FICO in 1956, by the time they (and the three national credit bureaus — Equifax, Experian, and TransUnion) were ready to commercialize the first general-purpose credit score (the FICO Score) in 1989, the restrictions imposed by the FCRA and ECOA were well-established.
These constraints have created a narrow search space for lenders to innovate within over the last 60 years. Over that time, clever statisticians and data scientists have discovered a lot of what does and doesn’t work in credit risk decisioning, which has left the lending industry with a very mature and well-tested set of tools and best practices for determining who should and shouldn’t get a loan.
This is generally a very good thing — we know what works! — but it also tends to lead to rigid thinking.
When you talk to experienced credit risk professionals, you often hear some version of “that’ll never work” or “that’s not how we do things.”
This rigidity is understandable, but it misses a key point — constraints change.
Laws and regulations (and how they’re interpreted and enforced) change. Technology continues to advance up and to the right, unlocking capabilities that would have astonished messieurs Fair and Isaac.
It’s not right to say that there’s no room in the field of credit risk decisioning for innovation.
The right way to think about it is that there’s always room for innovation, provided that it’s done with sufficient knowledge of and respect for the lessons we’ve learned over the last 60 years.
So, our goal in this essay is to describe the process of developing and operationalizing credit risk models, explain how that process has been shaped (and constrained) by different regulations and technologies over the last six decades, and discuss where new technologies and regulatory developments are unlocking opportunities to improve the quality of our decisions.
Developing a Credit Risk Model
AI is all the rage these days, in financial services and outside of it. However, it’s important to remember that lenders have been applying specific techniques and technologies within the field of artificial intelligence (machine learning, most prominently) to the question of who to lend money to for decades.
AI/ML can help lenders save themselves money (through increased efficiency) and save their customers money (through better pricing of risk). The big question is, “how?”
Lenders usually start with credit bureau data. The virtue of this data is that it is A.) highly predictive, B.) FCRA-compliant, and C.) old enough and deep enough that lenders can backtest their models against it.
You start by purchasing a dataset from one of the bureaus and turning that into something that can be used for machine learning.
A critical step in the model development process is precisely defining your outcome (in the context of lending, this is usually delinquency or default) because it will ultimately dictate the performance of your portfolio.
You define it by making an explicit value statement about time. Concretely, this looks something like, “I want to predict the likelihood of default within the first 3 months.”
Whether or not you want it to be, the choice has important consequences to your portfolio, so choose it carefully.
For simplicity’s sake, let’s say you wanted to launch a 12-month installment loan to an underserved consumer market segment. You would start by getting historical data of other lenders’ loans from a credit bureau to build your model.
You will need to make sure you pull the data at two different time periods: (1) when the original application was made so you can use data that is relevant for underwriting (and so you don’t have forward-looking data resulting in data leakage) and (2) 12 months later (or whatever time period is appropriate for you) to check if the consumer defaulted on their loan.
Then, you’d clean the dataset into something that can be used for machine learning.
Once you have your dataset, you can start to run different Logistic Regressions or other classification-based machine learning algorithms to find hidden patterns and relationships (i.e., non-linear functions and interaction terms).
There’s a lot more to it, and you can expand on things in much more elegant ways to handle different phenomena, but for the sake of simplicity, this is essentially how it’s done.
Evaluating your Model
Once you have a model for predicting default, you need to figure out if it is any good (or, more accurately, if it will be an improvement over the existing model).
This is important because we already have an extraordinarily good model for predicting default in consumer lending — the FICO Score. Building a better-performing general industry credit scoring model than FICO is essentially impossible (FICO has a 60+ year headstart on you, and they employ some very smart people), but you don’t need to build a model that outperforms FICO for the entire industry. You just need to build a model that outperforms FICO for your specific product and target customer segment. This is difficult but doable. Indeed, most large consumer lenders have built custom in-house default models superior to FICO for their specific use case and they continue to be a competitive advantage for them.
(Read Alex’s essay on the eventual end of the FICO Score for more details on this front.)
So, how do you know if your model is an improvement (for your business) over the status quo?
It turns out that accuracy is an imperfect metric when you have a low default rate (or, more generally, when you have severe class imbalance). As an example, suppose you have a 5% default rate. That means 95% of your data did not default, so if your model predicted that no one defaulted, you’d still have 95% accuracy.
Without proper adjustment, this behavior is actually very likely to occur in your model, so we tend to ignore the accuracy metric, and instead, we focus on the rank order separation of the model.
To measure that rank order separation, there are four metrics industry professionals typically look at: Precision, Recall, the Kolomogorov-Smirnov (KS) Test, and Gini/AUC.
Gini/AUC has increasingly become the most popular. A good credit risk model is usually around 70% AUC / 40% Gini. You don’t need to understand what that means; just trust Francisco — the higher, the better.
An important point here is that any single metric is very crude, and a dataset can be pathologically constructed to break it, so while these metrics are helpful, there are cases where things can still misbehave even though they seem normal. So, make sure to validate your model with sound business judgment.
But, for argument’s sake, let’s say you’ve done that. You’ve built a model that is better at rank ordering risk of default for your 12-month installment loan product than any of your prior models or the general industry models available from FICO or the bureaus.
Yay!
Now, what do you do?
Building a Compounding Analytic Advantage
Turns out, everything we’ve been discussing so far is the easy part.
The hard part is operationalizing our new model in a way that creates a compounding analytic advantage over time.
This is not a concept that William Fair and Earl Isaac would have grokked.
Back in their day, model development and model execution where two completely different processes, playing out in parallel.
Statisticians would pull data sets from the bureaus, look for hidden patterns and relationships within the data, develop features, and build a model. That model would then be deployed into production, where it would be called on to assist with a specific step (credit decisioning) within a much larger, human-powered workflow (relationship lending). That workflow would then produce outcome data (how did the loans perform?), which would be fed into the credit bureaus and aggregated into credit reports, which the statisticians would then draw on to start work on the next iteration of their model.
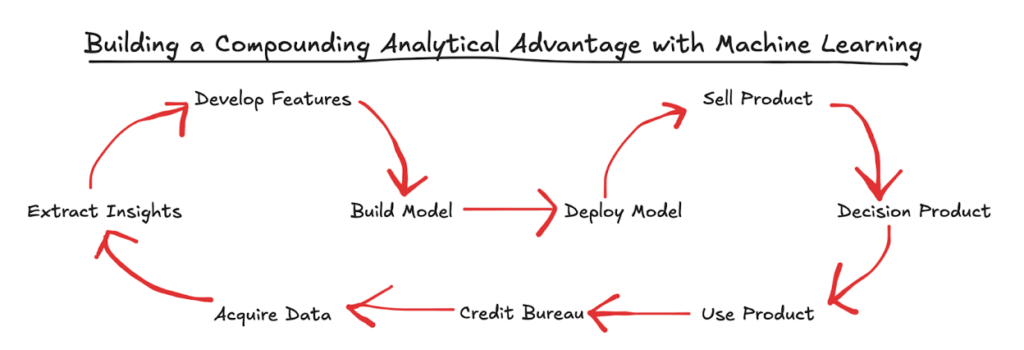
The process was slow — any use of computer systems for pulling applicant data or making credit decisions using statistical models happened in batch; there was no concept of real-time transactions — and reliant on industry-wide data aggregation (through the credit bureaus). There was little ability for individual firms to build what Francisco calls a “machine learning flywheel.”
Fast forward to today, and the big difference that we see is that the lending products that customers acquire and the experiences that they have using and managing them are all entirely orchestrated by software.
This allows for a much more tightly integrated and proprietary approach to model development, in which every interaction that the customer has with the product generates data, which can then be fed back in to improve the model, which can then be deployed to generate better, more personalized product experiences for the customer. And on and on and on.
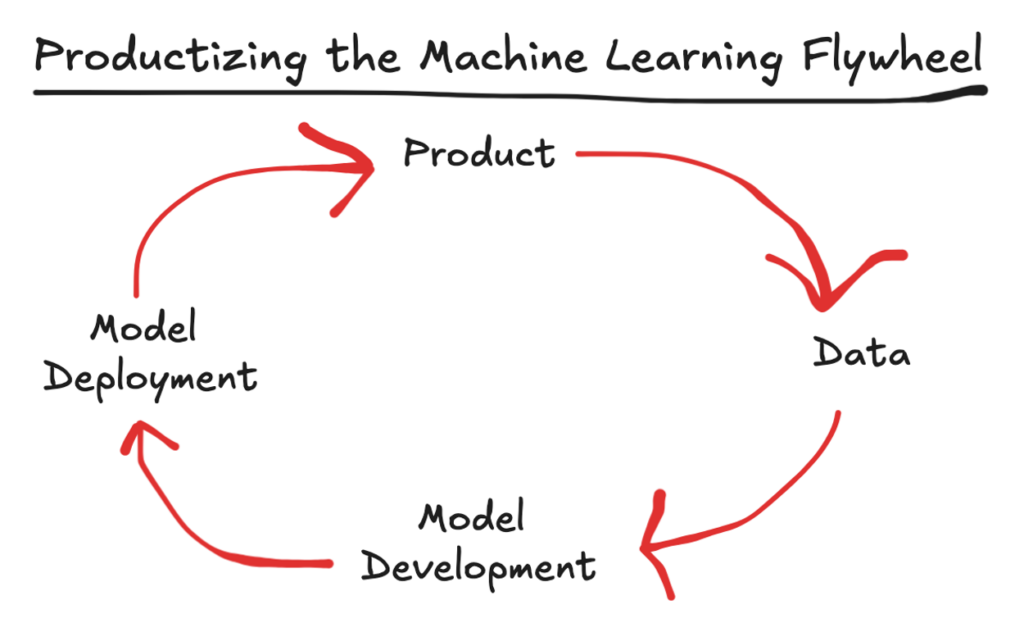
(Read this article from Francisco for a deeper dive into the challenges and rewards of building a machine learning flywheel.)
Now, to be clear — building this flywheel is not easy.
The foundation is a great product. None of this works if you don’t build a great digital lending product, and building a great digital lending product requires meticulous and thoughtful engineering, complemented by a deep understanding of the business.
But again, for argument’s sake, let’s say that you’ve succeeded in doing this. You built a great 12-month installment loan product for an underserved customer segment in the market.
How do you architect the systems around that product to create this compounding analytic advantage we’ve been talking about?
It starts with the data.
Data
Machine learning relies on data. When making credit risk decisions, bad data will ruin your business, while good data (especially good data that only you have or understand) can help you outperform the market.
Historically, credit risk models relied on loan repayment data from the bureaus (which is just a customer’s repayment history on another lender’s portfolio). Some lenders would complement this data with proprietary internal data, which offered more valuable and granular insights, but in general, bureau data was the center of gravity for all credit risk models.
However, in today’s world, in which the lending products themselves can generate proprietary data continuously in real time, this isn’t necessarily true.
There are a few different examples of this in fintech, which are worth paying attention to.
The first is product design. By iterating on the parameters of the lending product (loan amount, repayment terms, pricing, etc.), lenders can create low-risk product structures that can quickly produce useful proprietary signals for determining the risk of default. This is exactly what BNPL providers like Affirm, Afterpay, and Klarna did with the Pay-in-Four BNPL product, which is why these providers have traditionally not relied on or contributed to the traditional credit bureaus.
The second example is consumer-permissioned data. Fintech companies like Plaid, Finicity, and MX have helped to popularize and standardize the ability for consumers to share their financial data with authorized third parties. This ability (frequently referred to as open banking) is about to be codified by the CFPB’s Personal Financial Data Rights Rule, which is intended (among many other goals) to help improve consumer outcomes in lending via cash flow underwriting. It turns out that cash flow data (the patterns of in-flows and out-flows of money in consumers’ bank accounts) can result in a powerful set of features for predicting risk, which is why forward-thinking lenders are thinking very hard about ways to rearchitect their lending products in order to incentivize and easily facilitate consumer-permissioned data sharing.
(Read Alex’s essay on everything you ever wanted to know about cash flow underwriting for, well, everything you ever wanted to know.)
The third and final example is embedded lending. By distributing lending products within the context and workflows of non-finance activities, lenders can significantly reduce adverse selection and can take advantage of proprietary data that the embedded channel provider has about its customers.
A word of warning — utilizing novel forms of data, even when used as a complement to traditional bureau data, can be hazardous if it’s not done with extreme caution. The reach of fair lending laws is longer than many in fintech might expect and can be applied in ways that might not seem logical or intuitive (e.g., disparate impact).
That said, many of these new types of data are being operationalized in ways that provide a compliant path forward (FCRA-compliant data and attributes are very common in the world of cash flow underwriting these days). And many others can still be utilized in non-FCRA contexts (fraud, marketing, etc.) that provide tremendous franchise value to lenders.
Designing Credit Risk Machine Learning Systems
We’ve talked about how to develop a model and how to generate or acquire differentiated data that can strengthen that model, but we haven’t talked about how to integrate it into the systems used by the lender to make credit decisions.
So now we should talk about decision engines.
Just like you, risk models didn’t fall out of a coconut tree. They live in the context, terribly burdened by what has been. That context is public policy, regulatory requirements, and the business requirements of the line of business leaders that own the lending products that these risk models were built to support.
Lenders encode that context in a decision engine, which typically offers the ability to call third-party data sources and other internal services, run feature extraction, and execute model inference.
From an engineering perspective, these decision engines play a central role in orchestrating the larger loan underwriting workflow, which is (as this graphic from Francisco aptly illustrates) often quite chaotic:
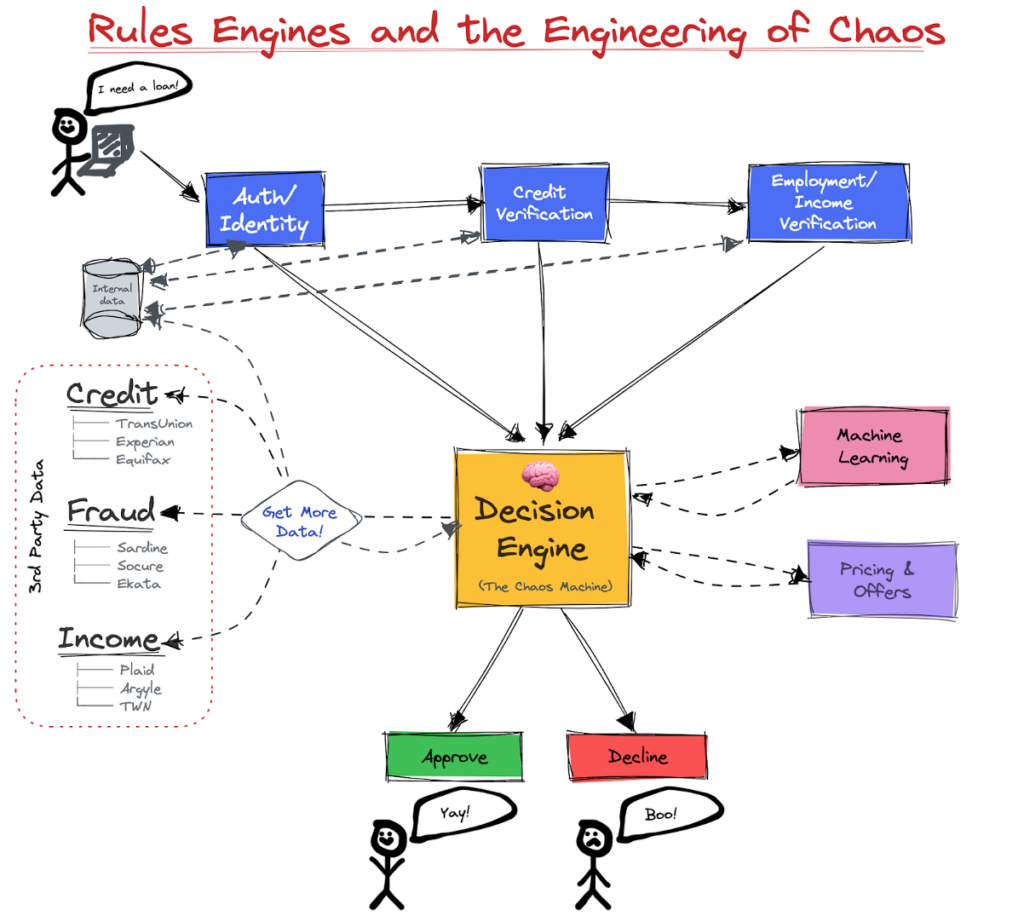
This chaos is, to a degree, to be expected (lending money is a complex business!), but it’s enormously beneficial to lenders if they can apply good systems engineering to rein in this chaos as much as possible and prevent their credit risk modeling and decisioning infrastructures from becoming brittle or difficult to change.
Here’s one view of what a well-organized architecture for a credit risk decisioning environment could look like (again, courtesy of Francisco):
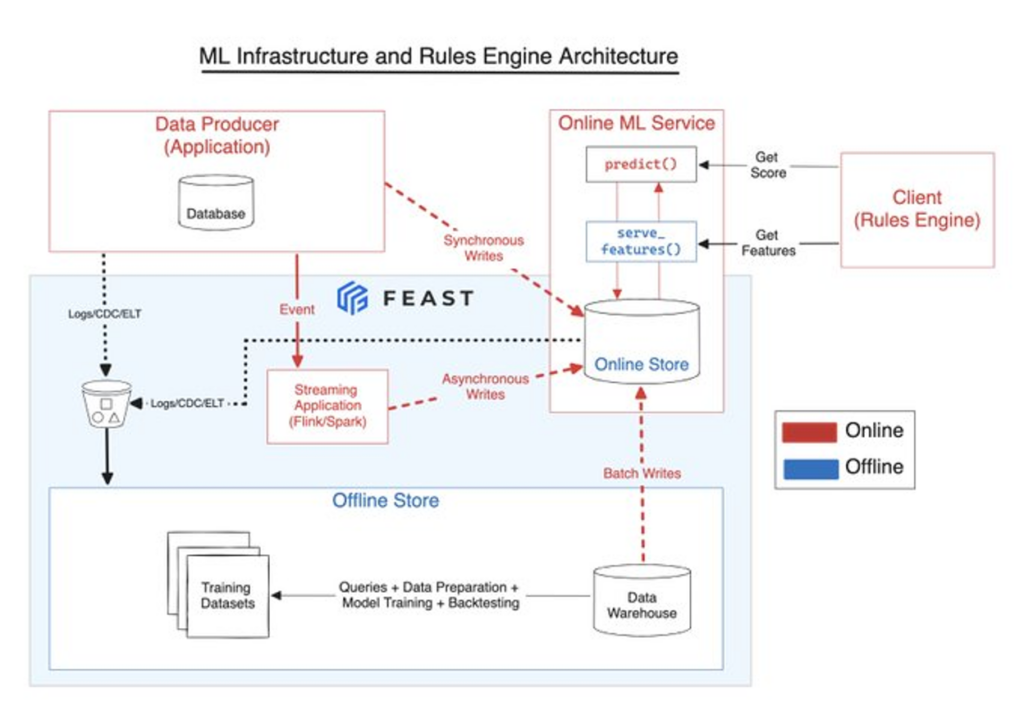
(If you are wondering what Feast is, it’s an open-source feature store that Francisco has been working on that is designed to help address some of the challenges that arise when deploying machine learning models into production.)
It also may be enormously beneficial to lenders if they can figure out how to apply generative AI to Francisco’s graphic above.
The Generative Emergence
Generative artificial intelligence has emerged as one of the most extraordinary innovations of the 21st century. But not every problem is a nail and using LLMs as a blunt hammer for everything could lead to consequential mistakes.
For example, using Gen AI for synthetic data generation is great for many applications (e.g., question answering based on existing documentation). Credit is not one of them.
On the other hand, using Agents (i.e., autonomous software to execute some set of configured operations) to 10x your data scientists or machine learning engineers building your models can be extremely powerful. This is basically a copilot, and tools like Julius.ai are doing this today.
However, the highest impact use case for Gen AI-powered agents is document verification and parsing.
Document verification is well positioned for automation as it is often a high-friction, manual task that results in a meaningful drop-off in the customer funnel. Small percentage changes could add up to meaningful conversion amounts for lenders and, while this space is still early, could be one of the biggest impact areas over the next five years.
Closing Thoughts
Nothing in the world of credit risk decisioning is easy. However, if we were to rank order the jobs to be done in credit risk decisioning from least challenging to most challenging, that list would be:
- Developing a proprietary credit risk model that outperforms off-the-shelf models for your specific product and target customer segment (difficult, but also relatively straightforward given the small search space that you are building within).
- Deploying that credit risk model into production in a way that doesn’t infuse more chaos into an already chaotic system (confoundingly difficult, especially at a large scale … but still achievable; check out this Feast demo from Francisco to see a glimpse of what a production ML system wielding chaos through great engineering and open source software can do).
- Architecting lending products and credit risk decisioning environments into a flywheel that produces a compounding analytic advantage (very few banks or fintech lenders have really figured out how to do this, and the ones that have are intentionally very quiet about it).
The focus that many folks who are new to lending or financial services have on #1, relative to #2, reminds us of that Omar Bradley quote, “amateurs talk strategy; professionals talk logistics.”
However, it’s only by mastering #1 and #2 that lenders can begin to reach for #3 and start down the path of building a great lending business.
Happy Risk Taking!
– Alex and Francisco
