
Editor’s Note — This article is sponsored by Nova Credit. As with all sponsored content in Fintech Takes, this article was written, edited, and published by me, Alex Johnson. I hope you enjoy it!
There was a time, not that long ago, when the idea of leveraging consumer-permissioned bank transaction data to understand prospective borrowers’ cash flow and use that insight to inform lenders’ credit risk decisions was considered novel; a step that fintech companies and other non-bank lenders might take, when underwriting higher-risk consumer segments, but that mainstream financial institutions wouldn’t bother with.
Those days are long gone.
Today, most credit risk executives across banking and fintech acknowledge the obvious truth — that cash flow data is incredibly valuable in lending (for all consumer segments), and, thanks to the maturation of open banking infrastructure, more accessible than ever.
The more interesting question now is not about belief. Everyone believes in the value of cash flow data. It’s on everyone’s roadmap.
It’s about adoption; about where it is on the roadmap.
Because here’s a truth that we need to acknowledge: The use of cash flow data in lending has a strong ROI, but it also introduces real operational challenges.
This tension will define 2026.
How do lenders integrate cash flow data across the consumer credit lifecycle? What use cases do they start with, and what use cases do they build towards over time? How do they generate value from those use cases without wrecking the finely-tuned digital lending workflows that they’ve built over the last couple of decades? How do they ensure that they’re ahead of the market on the adoption of different cash flow lending use cases, rather than behind it?
To answer these questions, we need a map.
Value vs. Cost
To oversimplify a bit, every conversation about cash flow lending use cases can be reduced down to a trade-off between cost and value.
Picture it as a scatterplot, with value on the horizontal axis and cost on the vertical axis.
Generally speaking, the most valuable cash flow lending use cases are those where the data is applied as broadly as possible, because cash flow data is both an excellent substitute for traditional credit data (for thin and no-file consumers) and a compelling orthogonal complement to traditional credit data (for full-file consumers).
The most valuable cash flow lending use cases are also those that most directly contribute to revenue generation, which means that underwriting-centric use cases tend to be the most valuable, although servicing and collections use cases are becoming more valuable as financial institutions prioritize customer retention and focus on revenue generation through cross-sell.
From a cost perspective, there are two major categories to consider.
The first are the hard costs that come from integrating data, developing, deploying, and maintaining new analytic features and models, and updating digital lending systems and workflows.
And then there are the soft costs incurred by changing digital lending workflows to accommodate the new steps in the process, such as data permissioning. These soft costs are not measured in dollars, but rather in incremental friction added to customers’ experiences. And given the extreme lengths that many lenders have gone to in order to optimize their digital lending experiences (particularly within the origination phase of the customer lifecycle), any additional friction that is added back in as a result of permissioning access to cash flow data can end up being extremely expensive for lenders.
Now, you might assume that the adoption curve, from one cash flow lending use case to the next, is likely to be linear, steadily progressing from low cost/low value to high cost/high value:
In the aggregate, across all lenders over a long time horizon, I think this will be true.
However, the important thing to remember about scatterplots is that while they often average out into a nice linear progression, the individual data points tend to be a lot messier:
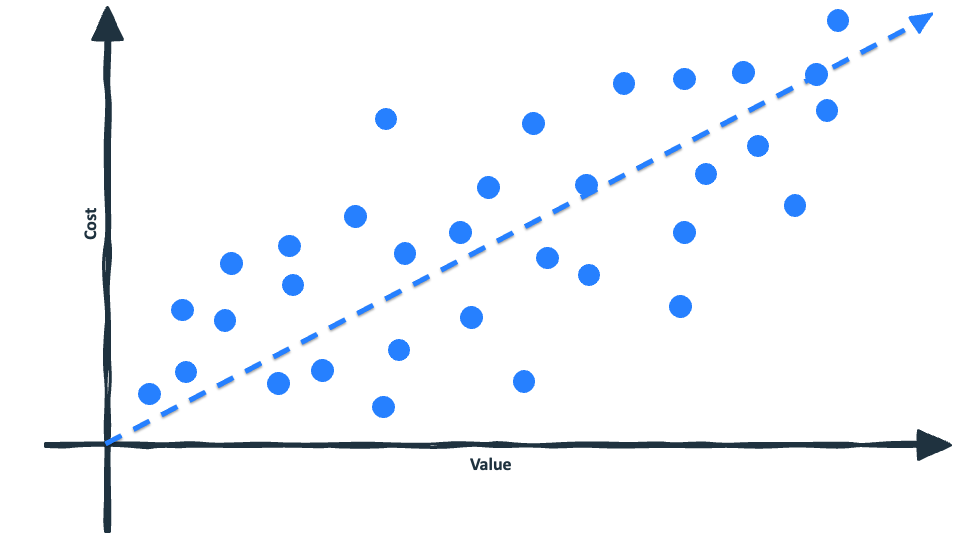
This is important to keep in mind when it comes to the adoption of cash flow data in consumer lending. At an industry level, we are all headed in the same direction. Eventually, it seems likely to me that most lenders will have permissioned cash flow data built in, for all customers, across the entire consumer credit lifecycle.
However, we’re not close to that endstate yet. And in 2026, the cash flow data adoption curves of individual lenders vary wildly based on their strategic goals, target customers, risk tolerances, and technical and analytical sophistication.
I want to be clear: There is no one-size-fits-all path. Every lender’s adoption of cash flow data will be, to some extent, unique, and I am not here to argue otherwise.
What I would like to do is to draw upon the experiences of early adopters (which I have learned about through a series of great conversations) to help shape the way that lenders think about the challenges and opportunities ahead of them.
Getting Started
If you ask a room full of credit risk executives where to begin with cash flow data, the most common answer you’ll hear is second-look underwriting.
It sits intriguingly far to the right on the value axis and comfortably low on the cost axis:
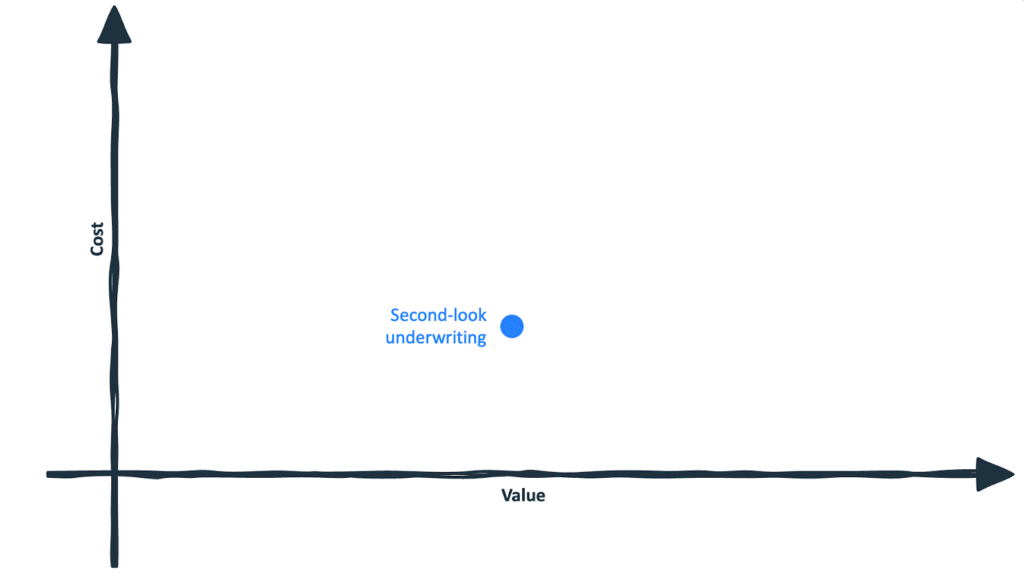
Rather than disrupting the core underwriting workflow, lenders deploy cash flow data only for applicants who narrowly miss approval thresholds. The pitch to the customer is straightforward: connect your bank account to improve your approval odds. That framing creates a clear value exchange and limits friction to a subset of marginal applicants. Operationally, second-look programs are appealing because they leave primary underwriting models intact, contain integration complexity, and allow institutions to demonstrate lift without re-architecting their decision engine.
It is, in many ways, the obvious starting place.
But obvious does not always mean optimal.
Second-look strategies carry structural limitations that can constrain their upside. By definition, the population being evaluated has already been rejected by the primary underwriting model. You may approve more applicants, but you are still working within a segment the model initially deemed riskier, and you may see some effects from negative selection (i.e., the customers that go to the greatest lengths to get credit are often riskier than they appear).
At the same time, second-look programs leave value on the table. Cash flow data is not merely a substitute for thin-file consumers; it is analytically orthogonal to credit bureau data. Applied broadly, it can sharpen risk differentiation even among full-file, prime borrowers. Restricting its use to marginal declines means forgoing potential improvements across the whole loan book.
And the cost is not zero. Even a contained deployment requires data integration, feature engineering, model development, governance review, and workflow adjustments. Permissioning friction, even if limited to a subset, still exists.
That raises a more strategic question: if you are going to incur integration and modeling costs anyway, is there a way to move further to the right and increase value?
For some lenders, the answer is yes.
A Different Entry Point
For institutions with deposit relationships, on-us underwriting represents a different entry point.
In this use case, lenders leverage transaction data from customers who already bank with them. No additional permissioning step is required. The lender owns the data. From a customer experience perspective, friction is effectively zero.
From a hard-cost standpoint, integration and analytics investments may look similar to a second-look strategy. Data must be acquired from other silos within the organization (for some institutions, this can be more daunting than acquiring external data), models must be developed, and decisioning systems must be updated. However, those investments are applied to a broader and often higher-quality population.
The value differential can be significant.
Rather than evaluating a negatively selected subset, the institution enhances decisioning across its existing customer base. It can improve risk-based pricing precision, confidently extend higher lines to strong customers, identify hidden risk within superficially prime profiles, and increase approvals without concentrating exposure in marginal segments.
On the scatterplot, this represents a move to the right (higher value!) without a meaningful move upward in cost.
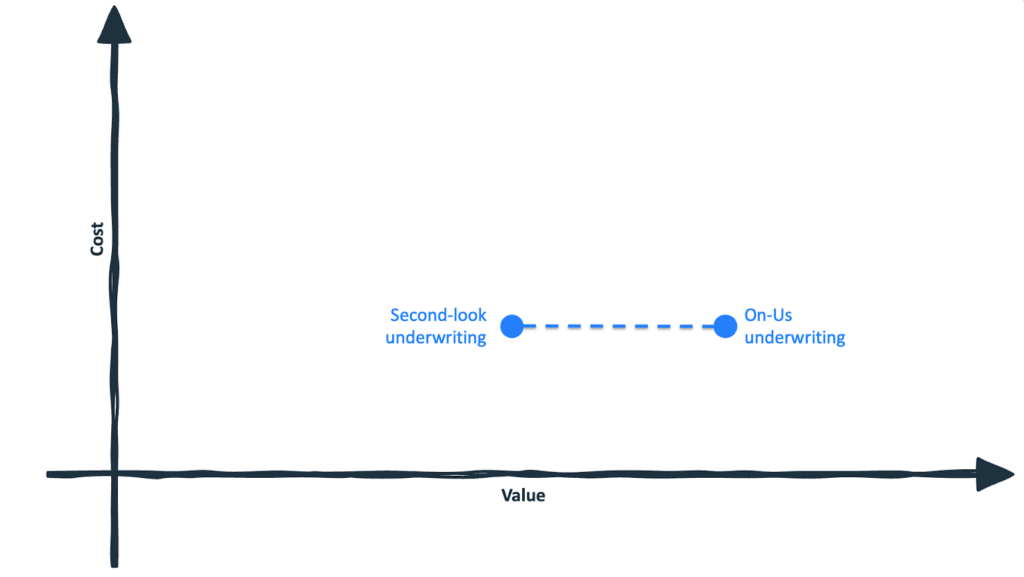
Of course, this option is not universally available. Monoline lenders and institutions without meaningful deposit franchises cannot leverage on-us data in the same way. But the broader lesson holds: the best first use case is not always the most obvious or intuitive one. Instead, it should be the one that maximizes incremental value relative to incremental cost given the institution’s specific assets.
For some lenders, that may be second-look underwriting. For others, it is on-us underwriting.
Moving Further to the Right
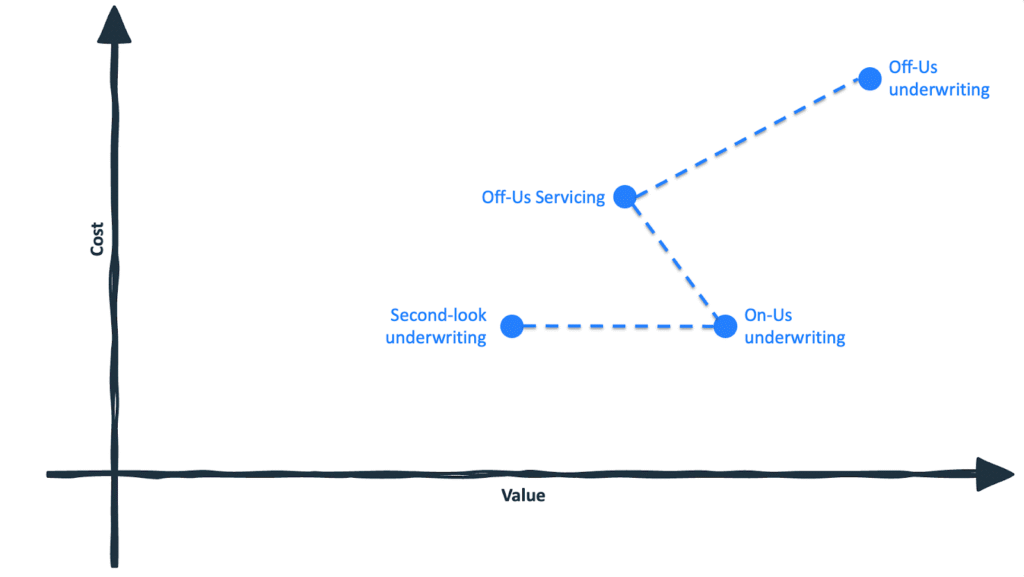
The real frontier, however, lies further along the curve.
The greatest potential value in cash flow lending comes from integrating off-us transaction data into the underwriting process at the top of the waterfall, for all applicants for whom the lender lacks on-us deposit data. This is the top-right corner of the scatterplot: broad application, maximum predictive lift, and direct impact on approvals, pricing, and portfolio construction.
It is also the most operationally complex and strategically risky move a lender can make.
Integrating off-us data at origination requires solving several problems simultaneously. The institution must design a permissioning experience that does not meaningfully harm conversion rates, manage outcomes when customers refuse to connect accounts (or when connections fail), build and validate new models, align risk and compliance stakeholders, and recalibrate risk appetite. All of this happens at the most sensitive point in the lifecycle: acquisition.
The top-right corner is intimidating. Very few institutions leap there directly.
A Strategic Detour: Learning Before Leaping
Rather than jumping straight to full off-us underwriting, lenders could consider a move up and slightly left, into servicing use cases that require off-us integration but do not carry the same risk.
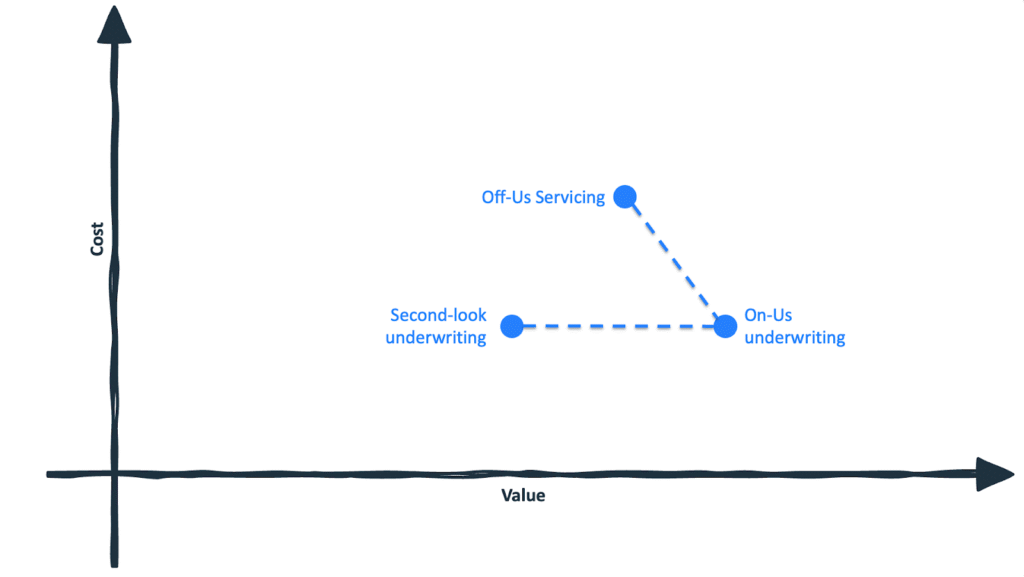
Line assignment and line management are common examples. In these scenarios, lenders request permissioned transaction data from existing customers and use it to optimize line increases, detect early warning signals, or refine retention strategies.
The value is lower than full off-us underwriting. The use case applies to a narrower population and has less immediate impact on revenue generation. But the integration and analytics costs are comparable. And that is precisely why this step is powerful.
Servicing use cases allow institutions to practice designing high-conversion permissioning flows, understand consumer willingness to connect accounts, build transaction data pipelines, develop feature engineering expertise, and stress-test governance frameworks, all in a lower-risk environment.
They create space to learn.
And learning compounds.
Beyond ROI: Sequencing as Strategy
If adoption were purely about optimizing the value-to-cost ratio of individual projects, lenders would simply rank use cases by projected ROI and move down the list.
But in order to realize the full transformational effect of cash flow data, you have to think beyond short-term ROI.
Sequencing matters.
Capabilities built for one use case reduce the cost and risk of the next. Improvements in permissioning UX increase take-up rates for future implementations. Feature libraries developed for servicing accelerate underwriting model development. Governance frameworks established early shorten approval timelines later.
Each step reshapes the map itself. What initially looked like a steep vertical move becomes less costly once the organization has built institutional muscle.
The strategic question, then, is not simply which use case has the highest ROI today. It is which use case allows the institution to develop capabilities that it can build on top of later?
Servicing use cases often fit that description. They provide a controlled environment to integrate off-us data without placing the entire credit box at risk. They generate incremental revenue and insight. And they prepare the organization for more consequential moves.
By the time a lender transitions into full off-us underwriting at the top of the waterfall, it is no longer a leap into the top-right corner. It is the logical next step in a deliberate sequence.
Ultimately, cash flow lending adoption in 2026 is not a question of belief or even of use case-specific ROI.
It is a question of sequencing.
Every lender is headed toward broader, lifecycle-wide integration, but the path matters.
The lenders that treat each deployment as a capability-building step — choosing use cases not just for immediate lift, but for what they enable next — will steadily reduce the cost and risk of moving further up and to the right. Permissioning expertise, analytics infrastructure, governance confidence, and organizational alignment all compound. Over time, what once looked like a dangerous leap into full off-us underwriting becomes a natural progression.
The institutions that understand this and act accordingly won’t just adopt cash flow data. They’ll build the muscle to win with it.


